Analyzing and Modeling Spatio-Temporal Dependence of Cellular Traffic at City Scale
Date: 2015.06.12
Tag: [Spatil-temporal dependence], [Traffic modeling], [Model measurement], [Correlation analysis], [Tide effects]
- 1. Why this paper
- 2. Paper Summarization
- 3. Take Away
1. Why this paper
- SKT 트래픽 예측 논문 레퍼런스 조사
- 트래픽 시/공간 관계 조사
2. Paper Summarization
2.1 연구 주제는?
2.1.1 연구 주제
- 도시 규모의 셀룰러 네트워크에서 트래픽의 시공간 의존성을 분석하과 이를 모델링함으로써 트래픽 특성을 정량적으로 파악하는 것
2.1.2 Contribution
- 최초로 실제 상용 데이터에서 셀룰러 트래픽의 시공간 의존성을 이해하기 위한 노력을 함
- 트래픽 의존성에 대한 몇 가지 특성을 발견함
2.1.3 주제 선택 이유
- 셀룰러 네트워크는 사용자 이동성과 비선형 트래픽 분포 특성으로 인해 비균질성과 시간적 변동성을 보임. 기존 연구는 시간적 특성이나 공간적 특성 중 하나에만 집중하거나 두 특성을 독립적으로 다루는 경우가 많았음. 그러나 셀룰러 트래픽은 시간과 공간 간 상호작용을 반영해야 더 정확한 네트워크 모델링 및 자원 최적화가 가능함. 본 연구는 도시의 대규모 데이터를 통해 이러한 상호작용을 분석하고, 네트워크 설계와 관리에 필요한 인사이트를 제공하기 위해 주제를 선택
2.2 연구의 목표는?
- 도시 규모의 셀룰러 트래픽 데이터를 분석하여 시공간 의존성을 파악
- 공간적 비균질성과 시간적 의존성을 통합적으로 고려한 모델을 개발하여 트래픽 패턴을 정밀하게 설명하고 예측 성능을 향상
- 개발된 모델을 통해 네트워크 자원 관리 및 최적화를 위한 실질적인 통찰 제공
2.3 연구 수행 방법은?
2.3.1 셀룰러 네트워크 구조
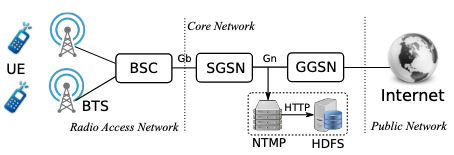
- 셀룰러 네트워크는 3개의 주요 부분으로 구성됨
- RAN: 사용자 장치(UE)와 기지국(BTS) 간 통신 담당
- Core Network: 데이터 패킷 라우팅(BSC \(\rightarrow\) SGSN \(\rightarrow\) GGSN)을 통해 모바일 네트워크와 인터넷 연결
- Public Network: 외부 인터넷 연결 제공
- 데이터는 Network Traffic Mining Platform(NTMP)에서 DPI를 통해 HTTP 로그를 추출 후 분석됨
2.3.2 사용 데이터셋
- 데이터셋 정보
- 수집 기간: 2012.08.20 - 2021.08.26, 7일간의 트래픽 데이터
- 수집 범위: 28 km x 35 km, 도시 중심 및 교외 포함
- 수집량:
- 13,000개 기지국에서 생성된 트래픽
- 452,000명의 사용자가 생성한 총 379백만 건의 HTTP 기록
- 데이터 특성:
- 각 사용자 활동은 기지국 좌표(위도, 경도)와 함께 기록됨
2.3.3.A Spatio-Temporal Foundation of Cellular Traffic
- 셀룰러 트래픽의 시공간 모델링
- 셀룰러 트래픽은 시공간 확률 과정으로 표현됨
- 특정 시공간 점에서의 트래픽:
- \(s\): 공간 인덱스
\(t\): 시간 인덱스
- 확률적 과정 정의:
- \(\mathcal{D}_{s}\): 공간 도메인으로 상호 배타적인 지역으로 나뉨
\(\mathcal{D}_{t}\): 시간 도메인으로, 동일 간격의 시간 구간으로 분할됨
- Spatio Temporal Covariance Function(STCF)
- \(E[Y(s, t) = \mu]\), 이고 \(Var[Y(s, t) = \sigma^2] \leq \infty\)일 때 공간적 차이 \(h\)와 시간적 차이 \(u\)에 따른 공분산 함수
- \(h = s_j - s_i\): 공간적 차이
\(u = t_j = t_i\): 시간적 차이
- 공간적 및 시간적 공분산 함수의 특별한 경우
- 순수 공간 공분산: \(C(\mathbf{h}, 0)\)
- 순수 시간 공분산: \(C(0, u)\)
- Correlation 함수: \(\rho(\mathbf{h}, u) = C(\mathbf{h}, u) / \sigma^2\)
- Emperical STCF
2.3.3.B Modeling Spatio-Temporal Dependence
시공간 데이터를 설명하기 위해 두 가지 모델링 전략이 제안됨
독립적 모델 (Separable Model)
공간적 의존성과 시간적 의존성을 독립적으로 계산함
- 공분산 함수: \(C(\mathbf{h}, u) = \sigma^s \rho(\mathbf{h}) \rho(u)\)
- \(\sigma^s\): 전체 트래픽 변동성을 나타내는 분산
- \(\rho(\mathbf{h})\): pure 공간적 공분산 함수
- \(\rho(u)\): pure 시간적 공분산 함수
공간적/시간적 공분산 함수 예시
- 지수 함수(Exponential)
거리 또는 시간 차이에 따라 상관성이 지수적으로 감소
- Cauchy 클래스(Cauchy)
- \(\alpha, \beta\): 파라미터로,상관성 감소 속도를 조정
더 유연하게 상관성 감소 패턴 설명 가능
- 비독립적 모델 (Non-Separable Model)
공간-시간 상호작용을 포함하여 복잡한 의존성을 설명
- \(\phi(x)\) - 완전 단조 함수 (Completely Monotonic Function) 정의
- 정의: 모든 차수의 도함수가 존재
- 조건: \((-1)^{n} \phi^{n} (r) \ge 0\)
- \(\psi(x)\) - 시간 효과 함수 (Tempoeral Effect Function) 정의
- 정의: 모든 시간 차수의 도함수가 존재
- \(\rho(mathbf{h}, u)\) - 공분산 함수 도출
- \(\phi(x)와 \psi(x)\)를 결합하여 비독립적 공분산 함수 정의
- \(\phi(x)\): 공간-시간 상호작용 설명
- \(\psi(x)\): 시간 효과 반영
- \(d\): 차원 스케일링 파라미터로 모델이 공간-시간 의존성을 조정
- 해석: 시간적 효과(\(\psi(u^2)\))가 공분산의 스케일을 조정하고, 공간적 차이(\(\lVert h^2 \rVert\))를 통해 공간-시간 간 상호작용 포착
- \(\phi(x)\) - 완전 단조 함수 (Completely Monotonic Function) 정의
- Gneting-Class 모델의 주요 특징
- 유연성:
- 기존 지수 함수 기반 공분산 함수보다 더 다양한 공간-시간 상호작용 패턴 설명 가능
- 특정 시간대 또는 거리에서 상관성이 급격히 감소하거나 완만히 감소하는 상황 모두 포착 가능
- 파라미터 추정:
- 모델 파라미터 \(\Theta\)는 log-likelihood 함수 \(L(\Theta \lvert \mathbf{O})\)를 최대화하여 추정
- \(\Theta\): 모델 파라미터 집합
- \(\mathbf{O}\): Spatio-Temporal observations
2.3.4 Exploratory Dependence Analysis
- 공간 분석 (Spatial Analysis)
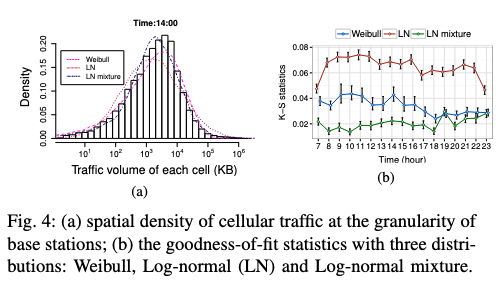
목적: 셀룰러 네트워크 트래픽의 공간적 의존성을 분석하여 기지국 간 거리와 트래픽의 상관성을 평가 후 공간적 비균질성(Spatial Inhormogeneity)를 이해
분석 과정:
- 기지국 단위 트래픽의 공간 밀도 분포를 분석하여 분포 특성을 파악
- 공간적 공분산 함수 \(\rho(h, 0)\)를 계산해 거리 \(h\)에 따른 상관성 감소 패턴 분석
Figure 4a: 기지국 단위 트래픽의 공간 밀도 분포
- 내용:
- 각 기지국의 트래픽 용량(로그 스케일)과 해당 빈도를 나타냄
- 대부분의 기지국이 낮거나 중간 트래픽을 처리하지만, 소수의 기지국에서 long tail로 나타나는 높은 트래픽 처리
- 내용:
Figure 4b: 분포 모델 적합도 평가
- 내용:
- Weibull, Log-normal, Log-normal mixture 분포를 데이터에 피팅하고 K-S 통계를 통해 적합도 비교
- 결과:
- Log-normal mixture 분포가 가장 적합하며, Weibull과 Log-normal은 상대적으로 덜 적합
- 내용:
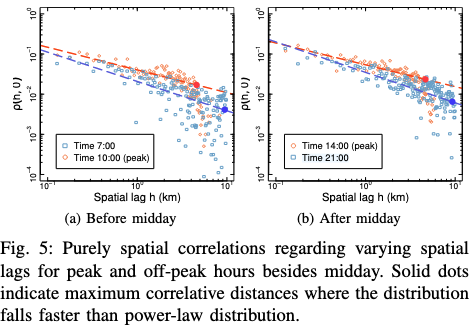
Figure 5: 분포 모델 적합도 평가
- 내용:
- 시간대(7AM, 2PM, 9PM)로 공간적 공분산 함수 \(\rho(\mathbf{h},0) \sim h^{\gamma_t}\)를 계산
- 각 시간대에 따라 상관성이 거리 \(\mathbf{h}\)에 따라 감소하는 패턴 시각화
- 결과:
- 피크 시간대(2PM): 상관성은 약 5km까지 유지되며 이후 급격히 감소
- 비피크 시간대(7AM, 9PM): 상관성은 약 10km까지 유지되며 더 완만히 감소
- 이는 출퇴근 및 점심시간과 같은 인간 활동 패턴에 의해 영향을 받음
- 내용:
- 시간 분석 (Temporal Analysis)
- 목적: 시간에 따른 트래픽 변화와 의존성을 분석하여 도심과 교외 지역의 트래픽 패턴 차이를 파악
- 분석 과정:
- 특정 지역(도심/교외)에서의 시간별 트래픽 변화를 관찰
- 시간적 공분산 함수 \(\rho(0, u)\)를 계산해 시간 간격 \(u\)에 따른 상관성 분석
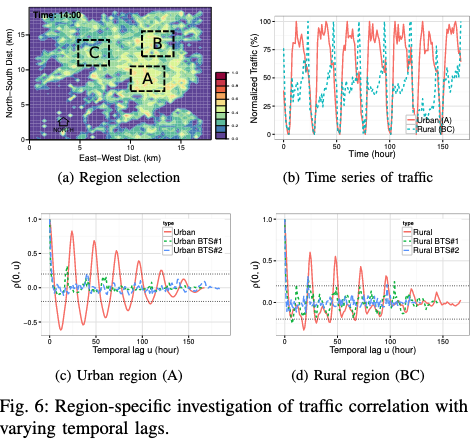
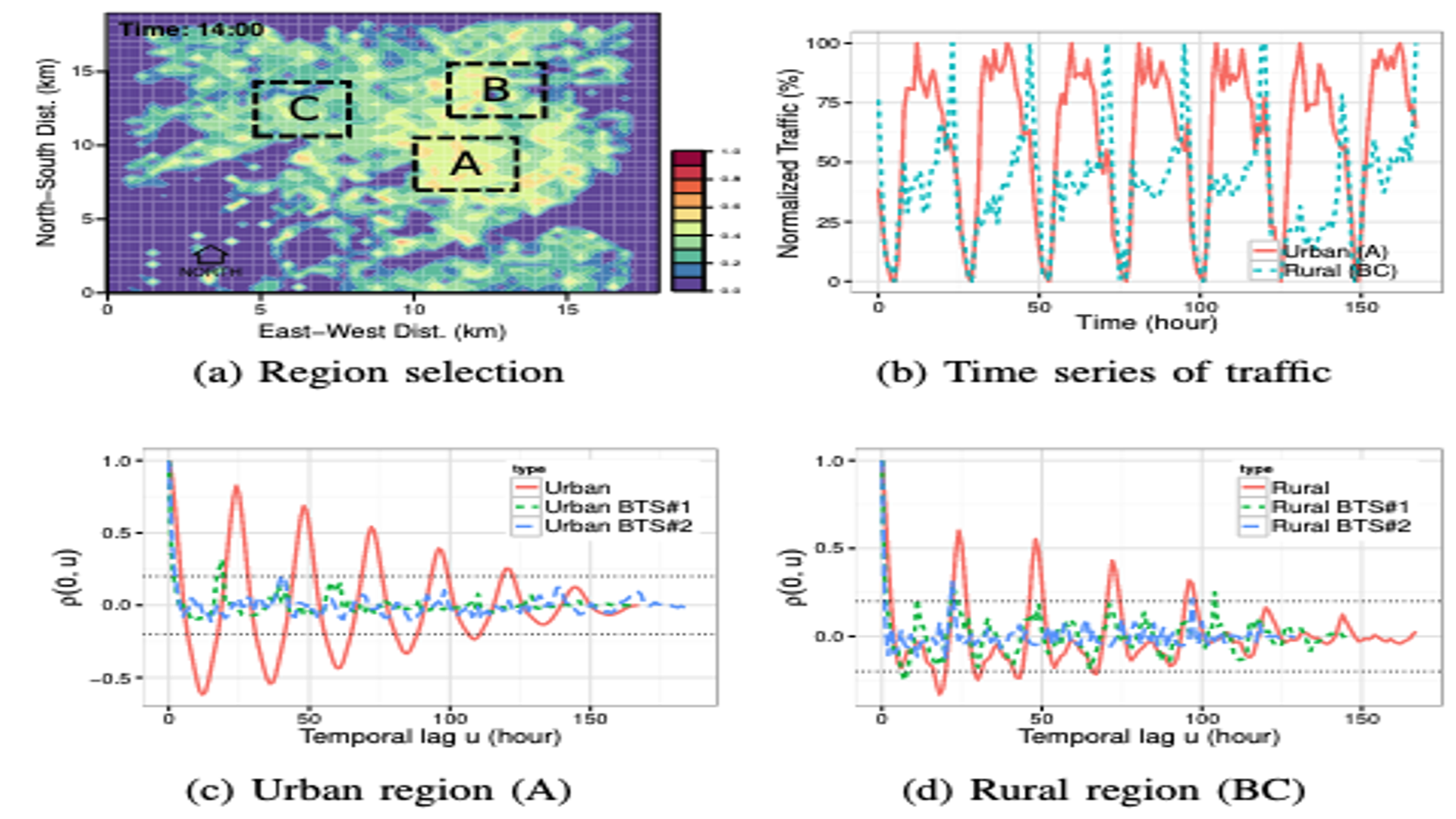
Figure 6a: 지역 구분
- 내용:
- 분석 지역을 도심(Region A)와 교외(Region B, C)로 나눔
- 도심은 상업 및 업무 지구, 교외는 주거 지역으로 정의
- 이 구분을 통해 각 지역의 트래픽 패턴 차이를 분석
- 내용:
Figure 6b: 시간대별 트래픽 변화
- 내용:
- 도심(Region A)와 교외(Region B, C)의 시간대별 트래픽 변화 비교
- 도심: 점심시간에 트래픽 최고치 도달
- 교외: 하루 종일 트래픽이 꾸준히 증가
- 이 차이는 인간의 이동 패턴과 밀접히 연결(출퇴근과 같은 “Tide Effect”)
- 내용:
Figure 6c & 6d: 시간적 공분산 함수(\(\rho(0, u)\))
- 내용: - 시간 간격 u에 따른 트래픽 상관성을 계산하여 도심(6c)와 교외(6d)의 패턴 비교 - 도심: 점심시간에 상관성이 강하며, 12시간 주기에서 반복적인 상관성 관찰 - 교외: 24시간 주기에서 강한 상관성이 유지되며, 도심보다 장기적인 패턴이 뚜렷
2.3.5 Modeling Spatial-Temporal Dependence
본 파트에서는 시공간 의존성을 모델링하는 방법과, 실험을 통해 각 모델의 성능을 평가한 결과를 다룬다. 특히, 공간적-시간적 상호작용을 효과적으로 반영하기 위해 독립적(Separable) 모델과 비독립적(Non-Separable) 모델을 비교하며, 각 모델의 특징 및 성능 차이를 분석한다. 주요 내용은 아래와 같다.
- 모델 파라미터 추정 (Estimation of Model Parameters)
- 모델 예측 성능 평가 (Evaluation of Prediction Performance)
- 모델링 결과 논의 (Discussions)
2.3.5.A Estimation of Model Parameters
- 지역별 의존성 모델을 사용하여 트래픽 특성의 차이를 반영
- Maximum-Likelihood Estimation(MLE)으로 모델 파라미터를 학습
- 계산 복잡성을 줄이기 위해 다음과 같은 제약을 설정
- 공간적 제한: 최대 5km 거리까지의 상관성만 반영
- 시간적 제한: 최대 6시간 이전의 데이터만 예측에 활용
- 이 제한은 피크 시간대에 상관성이 급격히 감소하는 경향을 반영
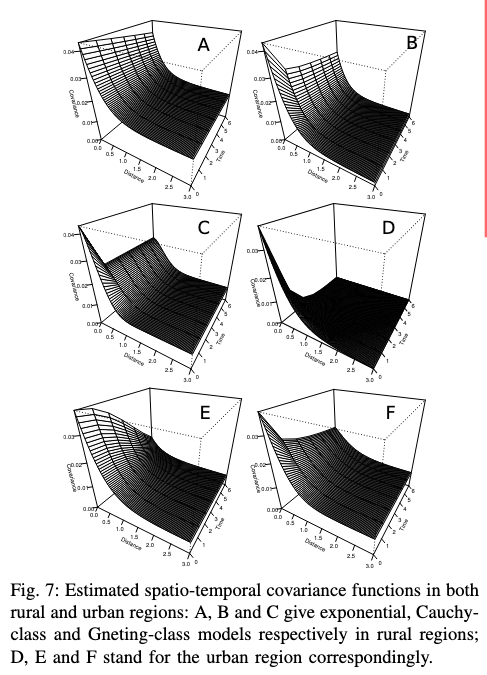
- 세 가지 공분산 모델(Exponential, Cauchy-class, Gneting-class)를 교외 및 도심 지역에서 비교
- 결과 해석
- 교외 지역:
- 공간적 거리 1km, 시간적 간격 2시간 이내에서는 세 모델 모두 높은 상관성을 보임
- 거리 및 시간 증가 시 모델 간 상관성 감소 속도가 다름
- Exponential, Gneting-class 모델: 완만한 감소
- Cauchy-class 모델: 급격한 감소
- 도심 지역:
- 시간적 상관성에서 세 모델의 차이가 두드러짐
- Gneting-class 모델: 완만한 감소, 가장 현실적
- Exponential 모델: 급격한 감소
- Cauchy-class 모델: 보수적 감소 성향
- 시간적 상관성에서 세 모델의 차이가 두드러짐
- 교외 지역:
2.3.5.B Evaluation of Prediction Performance
예측 방식
- 모델 파라미터는 하루 데이터를 기반으로 학습 후, 다음 6시간 동안의 트래픽을 예측
- 공간적으로는 지역을 10x10 그리드로 나누어 N = 100 블록을 사용
- 시간적으로는 T = 144(10분 단위)로 데이터를 분할하여 활용
성능 평가 지표: RMSE
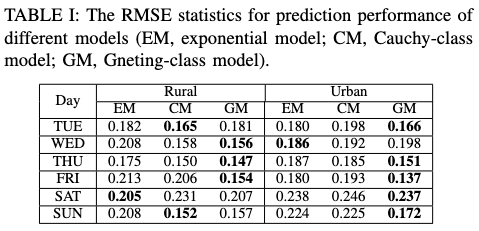
- 교외 지역
- Gneting-class 모델의 RMSE가 2.8% - 25.2% 감소
- 화요일과 주말은 Separable 모델이 약간 더 우수
- 도심 지역
- Non-separable 모델이 대부분의 요일에서 RMSE를 3.7% - 23.6% 감소
- Non-separable 모델의 성능 우위가 더 뚜렷
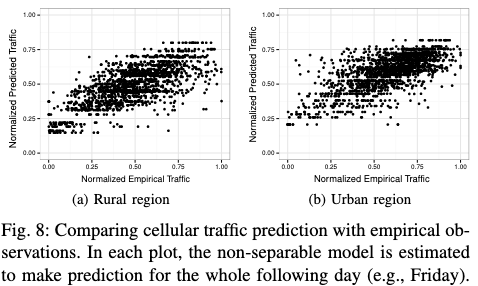
- 도심과 교외에서 Gneting-class 모델을 사용하여 예측한 셀룰러 트래픽과 실제 관측된 트래픽 간의 관계를 나타낸 산점도
- 점들이 대각선에 가까울수록 예측값과 실제값의 일치도가 높음을 의미
- 분석 내용
- 도심 지역
- 도심 지역의 트래픽은 중간 트래픽(0.5 - 0.75)에서 집중적으로 분포
- 산점도가 대각선에 가까운 점들이 밀집되어 있어 예측 정확도가 높음을 확인
- 원인 및 해석
- 도심 지역의 트래픽은 공간적 밀도가 높고, 정규화된 값의 중간 범위에 데이터가 집중됨
- 이는 Gneting-class 모델이 중간 트래픽 값에서 더 정확한 예측을 제공한다는 점을 시사
- RMSE 결과
- 도심 지역에서 Gneting-class 모델의 RMSE는 0.137로 교외 지역보다 낮음
- 이는 도심 지역의 트래픽 분포가 모델 학습에 유리하게 작용했음을 나타냄
- 도심 지역
- 주요 발견
- 부드러운 예측(Smoothing Effect)
- Gneting-class 모델은 트래픽 값의 극단적인 변동을 부드럽게 조정
- 실제값이 낮은 경우(\(x < 0.25\))에는 예측값이 약간 높게 나타나고, 높은 경우 (\(x > 0.75\))에는 예측값이 약간 낮아짐
- 이는 비독립적 모델의 구조적 특성에서 기인하며 극단적인 변동성을 완화함으로써 안정적인 예측을 제공
- 도심 vs. 교외 비교:
- 도심 지역:
- 중간 트래픽 값 구간(0.5 - 0.75)에 데이터가 집중되어 모델 성능이 더 우수
- RMSE가 0.137로 교외보다 낮음
- 교외 지역:
- 낮은 트래픽 밀도와 넓은 공간적 범위로 인해 예측의 어려움이 더 큼
- RMSE가 0.154로 도심보다 약간 높음 -음
- 도심 지역:
- Gneting-class 모델의 강점:
- 공간-시간 상호작용을 효과적으로 반영하여 예측 정확도 개선
- 교외 및 도심 지역 모두에서 독립적 모델(Exponential, Cauchy-class)보다 더 낮은 RMSE를 기록
- 부드러운 예측(Smoothing Effect)
2.3.5.C Discussions
Separable 모델
- 장점
- 수학적 간결성
- 공간적 공분산 함수(\(\rho(h)\))와 시간적 공분산 함수(\(\rho(u)\))를 분리하여 계산하므로 구현이 단순하고 계산 효율적
- 수학적 간결성
- 한계
- 상호작용 부족
- 공간과 시간 간의 상호작용을 반영하지 못함
- 서로 다른 시간대에서 공간적 상관성이 동일한 형태를 가지는 등 비현실적인 가정
- 조건부 상관성의 초기값 설정 문제
- 공분산 함수의 초기 조건(ex. \(\rho(h, 0)\)) 선택이 부정확할 경우, 모델링 결과가 왜곡될 가능성 존재
- 상호작용 부족
Non-Separable 모델
- 장점
- 복잡한 상호작용 반영
- 공간-시간 간의 상호작용 정보를 통합하여 현실적인 셀룰러 트래픽 패턴을 포착
- 더 복잡하고 다양한 의존성 설명 가능
- 복잡한 상호작용 반영
- 한계
- 계산 비용
- 모델 파라미터가 많고 구조가 복잡하여 학습 시간이 더 오래 걸림
- 과적합 위험
- 모델이 역사적 데이터에 지나치게 적합할 경우, 급격한 트래픽 변화에 대응하지 못할 가능성 존재
- 계산 비용
한계 극복 방안
- 크로스벨리데이션 및 부트스트랩
- 과적합 문제를 해결하고 모델의 견고성을 높이기 위한 일반적인 방법
- 다양한 데이터 샘플에 대해 반복적으로 학습 및 검증하여 모델의 신뢰성을 개선
- 클러스터 기반 의존성 모델링
- 지역별 또는 시간대 별로 서로 다른 모델을 설계
- 예: 도심과 교외 지역, 주간과 야간 시간대에 맞는 개별 모델 사용
- 이를 통해 복잡한 트래픽 패턴을 더 효과적으로 설명하며, 정확도와 견고성 간의 균형을 유지
- 지역별 또는 시간대 별로 서로 다른 모델을 설계
주요 시사점 및 결론
- 모델 선택의 중요성
- 독립적 모델은 단순성과 효율성을 제공하지만, 공간과 시간의 상호작용이 중요한 환경에서는 비독립적 모델이 필요
- 모델링 복잡성과 성능 간 균형
- 비독립적 모델은 더 높은 성능을 제공하지만, 계산 비용 증가 및 과적합 위험이 단점으로 작용
- 크로스밸리데이션 또는 클러스터 기반 접근 방식으로 한계 보완
- 맞춤형 모델링의 필요성
- 지역 또는 시간대의 특성을 반영한 맞춤형 모델을 활용하여 정확도와 견고성을 동시에 달성
2.3.6 Conclusion
연구 개요
- 본 연구는 도시 규모의 셀룰러 트래픽 데이터를 분석하여 시공간 의존성(spatio-temporal dependence)을 탐구
- 기존 연구가 강조했던 시간적 역학(temporal dynamics) 및 공간적 비균질성(spatial inhomogeneity)을 넘어, 두 요소 간의 상호작용을 포함한 새로운 관점을 제시
주요 발견
- 공간적 관점
- 셀룰러 트래픽은 이전 연구에서 가정한 uniformity을 위반
- 이로 인해 네트워크 자원 활용에 불균형이 발생할 수 있음
- 네트워크 시스템 설계 시 이러한 특성을 고려해야 대규모 시스템 장애를 방지 가능
- 시간적 관점
- 시공간 의존성을 반영한 네트워크 모듈은 혼잡을 사전에 완화할 수 있음
- 이는 네트워크 안정성을 높이고, 운영 효율성을 개선하는 데 기여
- 시공간 통합 정보의 중요성
- 공간적 및 시간적 데이터를 결합하여 상호작용 정보를 활용하면, 네트워크 시스템이 더 견고해지고 현실적인 시나리오에서 효과적으로 작동할 수 있음
Future Work
- 인간 이동성과 셀룰러 트래픽 간 연관성 연구
- 도시 내 집단적 인간 이동 패턴을 모델링
- 트래픽의 공간적 변화와 인간 활동 간 상호작용을 정량화
- 시공간 의존성 모델 혼합
- 목표:
- 서로 다른 지역 또는 시간대의 트래픽 특성을 반영하기 위해 모델 혼합(mixture models)을 도입
- 도전과제:
- 효율적인 경계 탐지 알고리즘 개발
- 특정 모델 파라미터를 추정할 수 있는 시공간 경계를 자동으로 감지
- 효율적인 모델 결합 알고리즘
- 여러 모델을 통합하여 계산 비용을 줄이고, 높은 성능을 유지
- 효율적인 경계 탐지 알고리즘 개발
- 목표:
3. Take Away
- 셀룰러 트래픽은 공간적 및 시간적 특성이 복잡하게 얽혀 있으며, 이를 반영한 네트워크 모델링이 필수적
- 인간 이동 패턴과 결합한 분석, 또는 지역별 맞춤형 모델링이 향후 연구의 중요한 방향으로 제시됨
- 시공간 경계 탐지 및 효율적인 모델 결합 알고리즘은 이렇나 연구를 뒷받침하는 핵심 기술이 될 것