Intent-Aware Radio Resource Scheduling in a RAN Slicing Scenario Using Reinforcement Learning
Date: 2021.06.14
Tag: [Radio resource scheduling], [RAN slicing], [Intent-aware scheduling], [Reinforcement learning]
- Abstract
- 논문의 구조
- 1. Why this paper
- 2. Paper Summarization
- 3. Take Away
Abstract
본 논문은 5G 및 그 이후의 네트워크에서 중요한 기술인 RAN Slicing의 효율적인 무선 자원 관리를 다룬다. RAN 슬라이스란 하나의 물리적 네트워크에서 여러 개의 가상 무선 네트워크가 독립적으로 작동하는 것을 말한다. 이 논문은 Online Convex Optimization이라는 새로운 방법을 통해 슬라이스 간의 무선 자원을 동적으로 배정하는 문제를 해결한다. 기존의 복잡한 모델 기반 접근법 대신, 이전 할당 데이터를 바탕으로 현재의 자원 배분을 학습하여 성능을 최적화하는 저복잡도 알고리즘을 제안한다. 시뮬레이션 결과, 이 방법이 기존 최적화 전략과 유사한 결과를 보이는 것으로 나타났다.
논문의 구조
- Introduction
- Related Work
- Communication System Model and Problem Formulation
- Proposed Intent-Aware RRS Using Reinforcement Learning
- Simulation Results
- Conclusion
1. Why this paper
- 통신 학회 동계 발표회 대비
- 오픈소스 시뮬레이터를 이용한 알고리즘 제작
1.1 What is the research topic and why was it chosen?
- 연구 주제: RAN 슬라이싱에서 Intent Aware Radio Resource Scheduling을 강화학습을 습용한 Radio Resource Management를 강화학습을 활용해 최적화
- 선택 이유
- 5G 네트워크에서는 서비스별로 다른 QoS 요구사항이 존재하여 네트워크 슬라이싱이 필수적
- 무선 자원이 제한적이므로 효율적 관리가 중요
- 기존 RRS 기법은 슬라이스별 의도를 충분히 고려하지 못하거나 변화하는 네트워크 상태에 적응하지 못하는 한계가 있음
- 데이터 기반의 동적 자원 관리가 필요한 상황
1.2 What are the objectives of the study?
- 목표 1: 슬라이스 간 자원 할당을 최적화하여 각 슬라이스의 QoS 요구를 충족
- 목표 2: Intent Drift를 방지하여 네트워크 상태 변화르 인한 QoS 위반 방지
- 목표 3: 실시간 네트워크 상태에 적응할 수 있는 동적 자원 관리 제공
- 목표 4: eMBB, URLLC, BE 슬라이스 별 고유한 요구사항을 지원
1.3 What methods were used to conduct the research?
- 강화 학습 방법: Soft Actor-Critic (SAC) 알고리즘을 사용
- 구체적 방법:
- 관측 공간 정의: 네트워크 상태와 슬라이스 QoS 요구사항을 포함하는 관측 공간을 설계
- 보상 함수 설계: 슬라이스별 QoS 요구 충족 여부를 평가하고, intent에서 벗어날 경우 이를 교정할 수 있는 보상 함수 설계
- 시뮬레이션 환경: QuaDRiGa 채널 시뮬레이션을 활용하여 현실적인 네트워크 조건에서 알고리즘 성능 검증
1.4 What results were obtained?
- 제안된 RL 기반 RRS 성능
- 기존 PF 및 RL 기반 방법들보다 우수한 슬라이스별 QoS 충족률 달성
- 네트워크 트래픽 변화에 따라 자원 할당을 동적으로 조정
- Intent Drift를 감지하고 교졍하여 네트워크 상태 변화에도 QoS 요구 유지
- BE 슬라이스의 long-term average throughput 및 5-percentile throughput이 목표에 근접하게 유지
1.5 What is the significance of the results?
- 의도 기반 자원 스케쥴링의 유효성 입증
- RAN 슬라이싱 환경에서 네트워크 성능을 극대화할 수 있음
- 결과의 주요 의의
- 적응성: 실시간으로 네트워크 상태 변화에 따라 자율적 자원 할당 가능
- 확장성: 다양한 슬라이스와 QoS 메트릭을 지웥하여 미래 네트워크에도 적용 가능
- 미래 연구 및 응용: 공개된 코드와 프레임워크는 지능형 네트워크 자원 관리와 자율 네트워킹의 기초가 될 수 있음
2. Paper Summarization
2.1 Introduction
- 연구 배경
- 5G 및 차세대 네트워크에서는 다양한 서비스의 요구를함지원하기 위해 네트워크 슬라이싱이 핵심 기술로 자리 잡음
- RAN 슬라이싱은 무선 주파수 자원과 같은 제한된 자원을 효율적으로 관리하여 각 슬라이스의 요구를 충족해야함
- 문제점
- 네트워크 슬라이스 간 무선 자원 스케쥴링은 다양한 SLA(Service Level Agreement)를 만족하는 것이 어려움
- 네트워크 트래픽의 변동성과 슬라이스별 QoS 요구의 상이함으로 인해 자원 부족 상황에서 최적의 자원 배분이 복잡해짐
- 목표
- Intent-aware 자원 스케쥴링 프레임워크를 제안하여 슬라이스별 QoS 목표를 효과적으로 충족하고 자원 배분을 최적화하는 것을 목표로 함
- 슬라이스의 QoS 요구를 SLA에 기반하여 정량적으로 표현
- 강화학습을 사용하여 실시간 네트워크 상태 변화에 적응적 자원 할당 수행
- Intent drift를 감지 및 교정하여 네트워크가 지속적으로 SLA 목표를 만족하도록 설계
- Intent-aware 자원 스케쥴링 프레임워크를 제안하여 슬라이스별 QoS 목표를 효과적으로 충족하고 자원 배분을 최적화하는 것을 목표로 함
2.2 Related Work
기존 연구는 RAN 슬라이싱 환경에서 Radio Resource Scheduling을 최적화하기 위해 다양한 최적화 기법과 기계 학습 기법을 제안함
2.2.1 Optimization-based Approaches
- Lyapunov 최적화
- Lyapunov 최적화 방법은 네트워크의 불확실성을 고려하여 자원 스케쥴링 문제를 최적화함[14]
- 장점: 이론적으로 안정성 보장
- 단점: 복잡한 네트워크 환경에서 비선형성과 불확실성 처리에 한계
- Earliest Deadline First(EDF)
- EDF 스케쥴링은 패킷 전송 시 마감 시간이 가장 짧은 요청을 우선적으로 처리하는 방법임[14]
- 한계: 네트워크 요구가 동적으로 변화할 때는 비효율적일 수 있음
- Markov Decision Process(MDP)
- MDP는 상태 전이 확률에 따라 최적의 결정을 내리도록 하는 기법으로 자원 할당 문제에 적용됨[15]
- 한계: 상태 공간이 커지면 연산 복잡도가 급격히 증가함
- Supervised Learning
- 네트워크의 과거 데이터를 바탕으로 자원 스케쥴링을 예측하는 방법[16]
- 한계: 새로운 환경이나 변화하는 트래픽 패턴에 적응하기 어려움
2.2.2 Data-driven Approaches using Reinforcement Learning
- 강화 학습과 RAN 슬라이싱
- RL은 네트워크 데이터를 기반으로 정책을 학습하여 자원 스케쥴링을 수행하며, 특히 5G 및 B5G 환경에서 유망한 방법으로 평가받고 있음
- 기존 강화 학습 기반 RRS 연구
- [9]의 연구
- 기법
- O-RAN 표준을 따르는 PPO(Proximal Policy Optimization) 기반의 강화 학습을 활용하여 슬라이스 간(inter-slice) 미 슬라이스 내(intra-slice) 자원 배분을 최적화함
- 특징
- eMBB, mMTC, URLLC 슬라이스를 고려
- 보상함수는 eMBB의 데이터 전송률을 최대화하고, URLLC의 버퍼 크기를 최소화하는 방식으로 설계됨
- 한계
- 각 슬라이스의 세부 의도를 고려하지 않고, QoS 요구사항을 일반적인 네트워크 메트릭 최적화로 단순화함
- 기법
- [10]의 연구
- 기법
- LSTM 기반의 심층 학습과 A3C(Asynchronous Advantage Actor-Critic) 알고리즘을 결합하여 슬라이스별 자율적 자원 할당 수행
- 특징
- 각 슬라이스에 독립적인 RL 에이전트를 두어 유연한 자원 관리 가능
- 자원이 부족할 경우 슬라이스 간 상호작용을 줄이도록 설계
- 한계
- 자원이 충분하지 않은 경우 모든 슬라이스에 부정적 보상을 주어 수렴이 어려움
- 기법
- [11]의 연구
- 기법
- DDPG(Deep Deterministic Policy Gradient)와 DQN(Double Deep Q-Network)을 결합하여 슬라이스별 자원과 전력을 최소화하는 2단계 스케쥴러를 제안
- 특징
- 상위 레벨 컨트롤러가 각 슬라이스의 최대 및 최소 전송률을 설정하고, 하위 레벨 컨트롤러가 실제 자원 할당을 수행
- 슬라이스별 QoS 성능을 고려한 가중치 기반의 보상 함수를 사용함
- 한계
- 슬라이스 간 우선순위를 명시적으로 설정하지 않으며, 네트워크 요구가 변할 경우 적응이 어려움
- 기법
- [12], [13]의 연구
- 기법
- SLA 만족률을 기반으로 자원 배분을 최적화하는 방법을 제안
- 특징
- [12]는 LSTM과 A2C(Advantage Actor-Critic) 알고리즘을 결합하여 슬라이스 대역폭을 동적으로 할당
- [13]은 Ape-X 기반의 분산형 심층 강화 학습을 사용하여 Resource Block 할당을 최적화
- 한계
- 슬라이스 간의 우선순위 설정이 명확하지 않으며, QoS 목표의 세부적인 정량적 측정이 부족함
- 기법
- [9]의 연구
2.2.3 기존 연구의 한계와 문제점
- 슬라이스별 Intent aware 접근 부족
- 기존 연구는 슬라이스의 QoS 목표를 정량적 의도로 구체적으로 정의하지 못함[9, 10, 11]
- 각 슬라이스의 목표가 명확하지 않으므로, 특정 메트릭의 최적화가 실제로 의도를 충족하는지 판단하기 어려움
- 보상 함수의 설계 문제
- 보상 함수가 특정 네트워크 메트릭만을 최적화하는 데 중점을 둬, intent drift를 인지하거나 교정하지 못함[9, 10, 11, 13]
- 슬라이스 간 우선순위 미고려
- 일부 연구에서는 슬라이스 간 자원 경쟁 시 우선순위를 명확히 설정하지 않아 중요한 슬라이스의 요구를 충족하지 못할 수 있음[11]
- 슬라이스별 상이한 메트릭 고려 부족
- 모든 슬라이스에 동일한 메트릭을 적용하거나 제한적인 메트릭만 고려하여 다양한 네트워크 시나리오에서 확장성이 부족함[9, 10, 11]
2.2.4 본 논문의 contribution
- Intent 기반 RRS 설계
- 본 논문은 각 슬라이스의 의도를 명확히 정의하고, 이를 QoS 목표로 변환하여 보상 함수에 반영
- Intent drift 감지 및 교정
- 네트워크 상태가 변화할 때 의도 드리프트를 자동으로 인지하고 보상 함수를 통해 이를 교정하공 메커니즘을 제공
- 슬라이스 간 우선순위 설정
- 가중치를 부여하여 중요한 슬라이스에 자원을 우선적으로 배정하며, 부족한 자원 상황에서도 QoS 목표를 최대한 충족할 수 있도록 설계
- 다양한 메트릭 지원
- eMBB, URLLC, BE와 같은 다양한 슬라이스 타입에 맞춤형 메트릭을 적용하여 확장성이 높은 RRS를 제공
2.3 Communication System Model and Problem Formulation
2.3.1 통신 시스템 모델
- 대규모 밀리미터파 MIMO 시스템
- \(C = \{1, 2, ..., C\}\)개의 셀로 구성된 네트워크를 가정하고, 타겟 셀(\(C_{target}\))에서 분석을 수행
- 송신 안테나 수: \(N_t\), 수신 안테나 수: \(N_u\)
- 대역폭 \(B MHz\)로 나뉘어진 주파수 자원은 Resource Block으로 세분화되며, 이를 Resource Block Group으로 묶어 관리함
- 슬라이스 구조
- 각 셀은 \(S={1, 2, ..., S}\)개의 슬라이스를 가짐
- 각 슬라이스 \(s\)는 동일한 QoS 요구를 가진 UE \(U_s = \{1, 2, ..., U_s\}\)로 구성됨
- 시간 단위
- 스케쥴링은 최소 시간 단위인 TTI \(t\)에 따라 수행되며 \(t_n = t \times n\)은 스텝 \(n\)에서의 시간값을 의미
2.3.2 네트워크 메트릭 정의
- \(RSRP_{b,u}\): 기지국 \(b\)가 UE \(u\)로 송신하는 기준 신호 수신 전력
- \(PL\): Path Loss
- \(SF\): Shadow Fading
- \(\vert \alpha_0 \vert ^2\): 안테나 이득
- \(\vert \alpha_{a,z} \vert ^2\): 경로 계수
- \(P_{u, b}\): 사용자 \(u\)가 기지국 \(b\)로부터 수신하는 전력
- Spectral Efficiency(SE)
- \(I^{b,u}_{inter}\): 셀 간 간섭
- \(\sigma^2\): 잡음 전력
- 간섭 전력 합 계산
- 타겟 셀 \(C_{target}\)에서의 간섭 전력은 주변 셀에서 발생하는 간섭의 합으로 주어짐
- \(max_{(6)}(RSRP_{i,u})\)는 타겟 UE \(u\)에 대해 가장 큰 간섭 신호를 제공하는 상위 6개의 기지국을 고려한 값임
- 간섭은 상위 6개의 기지국에서 오는 전력 합으로 근사하여 계산함
- Resource Block Group(RBG)
- \(\mathbb{R}\): step \(n\)에서 각 슬라이스에 할당되는 RBG의 집합
- \(R_{S}(N)\): step \(n\)에서 슬라이스 \(s\)에 할당되는 RBG 개수
매 step \(n\)에서 할당되는 RBG 개수를 합하면 \(R\)로 일정 \[\sum_{s=1}^{S} R_{s}(n) = R, \tag{5}\]
step에서의 RBG 개수가 \(R\)로 고정되어 있기 때문에 RBG 할당의 경우의 수는 아래와 같음 \[\mathbb{R}_{comb} = [\mathbb{R}_{comb}^{1}, \mathbb{R}_{comb}^{2}, ..., \mathbb{R}_{comb}^{\vert \mathbb{R}_{comb} \vert}], \tag{6}\]
- Throughput
- \(r_u(n)\): 사용자 \(u\)의 step \(n\)에서의 최대 throughput, 단위는 Mbps
- \(R_s^{u}(n)\): step \(n\)에서 슬라이스 \(s\)의 사용자 \(u\)에 할당된 RBG 수
- \(B\): 대역폭
- \(PS\): Packet Size
- \(SE_u(n)\): step \(n\)에서 사용자 \(u\)의 SE
- Effective Throughput
- 실제 전송된 데이터량을 나타내며, 버퍼에 존재하는 데이터량에 따라 제한됨
- \(b_u(n)\): 사용자 \(u\)의 버퍼에 저장된 데이터
- Buffer Occupancy(버퍼 점유율)
- 사용자 단말 버퍼의 점유 상태를 나타내는 메트릭
- \(b_{max}\): 버퍼의 최대 용량
- Packet Loss Rate(패킷 손실률)
- \(p_u(n)\): step \(n\)에서 사용자 \(u\)의 패킷 손실률
- \(m\): 패킷 손실률을 계산하기 위한 관찰 윈도우의 크기
- \(d_u(i)\): step \(i\)에서 손실된 패킷의 양
- \(b_u(i)\): step \(i\)에서 사용자 \(u\)의 버퍼에 남아있는 데이터양
- \(r_u^{rqt}(i)\): step \(i\)에서의 전송 요구량(required transmission rate)
- \(n \ge m\)인 경우: 관찰 윈도우가 충분히 확보된 경우
- 패킷 손실률은 최근 \(m\)개의 시간 스텝 동안 손실된 패킷의 비율로 계산됨
- 분자는 \((n-m)\)부터 \(n\)까지의 손실된 패킷 수를 합한 값으로, 손실된 총 패킷의 양을 의미함
- 분모는 \((n-m)\) 시점에서의 버퍼에 남아 있는 데이터량과 최근 \(m\)개 시간 step 동안의 전송 요구량의 합으로 구성
- 이는 해당 기간 동안 네트워크가 전송할 수 있었던 잠재적인 데이터량을 의미함
- \(n < m\)인 경우: 관찰 윈도우 초기 구간
- step \(n\)이 관찰 윈도우 \(m\)보다 작아, 네트워크 초반의 데이터만을 기반으로 손실률을 계산해야 함
- 분자는 \(i = 1\)부터 \(n\)까지의 손실된 패킷을 합한 값으로 초기 구간에서 발생한 손실을 반영
- 분모는 초기 버퍼 상태 \(b_u(1)\)와 초반부터 step \(n\)까지의 전송 요구량의 합
- Average Buffer Latency(평균 지연 시간)
- 버퍼에 저장된 패킷이 전송되기까지 대기한 평균 시간
- \(\ell_u(n)\): step \(n\)에서 사용자 \(u\)의 평균 버퍼 지연 시간
- \(i\): 지연 시간을 나타내는 인덱스
- \(l_u^u(n)\): step \(n\)에서 지연 시간 \(i\)를 가지는 패킷의 개수
- \(l_{max}\): 허용 가능한 최대 지연 시간
- Long-Term Throughput
- 일정 기간 동안의 평균 throughput을 계산함
- \(m\): 측정 윈도우 크기
- 마찬가지로 step이 관찰 윈도우와 클 때와 크지 않을 때로 나눌 수 있음
- Fifth-Percentile Throughput
- 하위 5%의 전송률을 나타내며 네트워크 최저 성능 보장에 사용됨
- \(P_{5\%}\): 하위 5% 값을 계산하는 함수
2.3.3 슬라이스 유형 및 Intent 정의
- eMBB 슬라이스
- 대규모 데이터 전송을 필요로 하는 서비스
- QoS 요구
- 최소 전송률: \(r_{eMBB}^{req}\)
- 평균 지연 시간: \(l_{eMBB}^{req}\) 이하
- 패킷 손실률: \(p_{eMBB}^{req}\) 이하
- URLLC 슬라이스
- 초저지연 및 높은 신뢰성을 요구하는 서비스
- QoS 요구
- 최소 전송률: \(r_{URLLC}^{req}\)
- 평균 지연 시간: \(l_{URLLC}^{req}\) 이하
- 패킷 손실률: \(p_{eMBB}^{req}\) 이하
- BE 슬라이스 (Best-Effort)
- 긴급하지 않은 트래픽
- QoS 요구
- 장기 평균 전송률: \(g_{BE}^{req}\)
- 5퍼센타일 전송률: \(f_{BE}^{req}\)
- 슬라이스의 평균 성능 메트릭
- \(SM_{s}\): 슬라이스 \(s\)의 평균 성능 메트릭
- \(U_{s}\): 슬라이스 \(s\)에 속한 사용자 단말의 총 수
- \(SM_{u}\): 사용자 단말 \(u\)에서 측정된 개별 성능 메트릭
2.4 Proposed Intent-aware RRS Using Reinforcement Learning
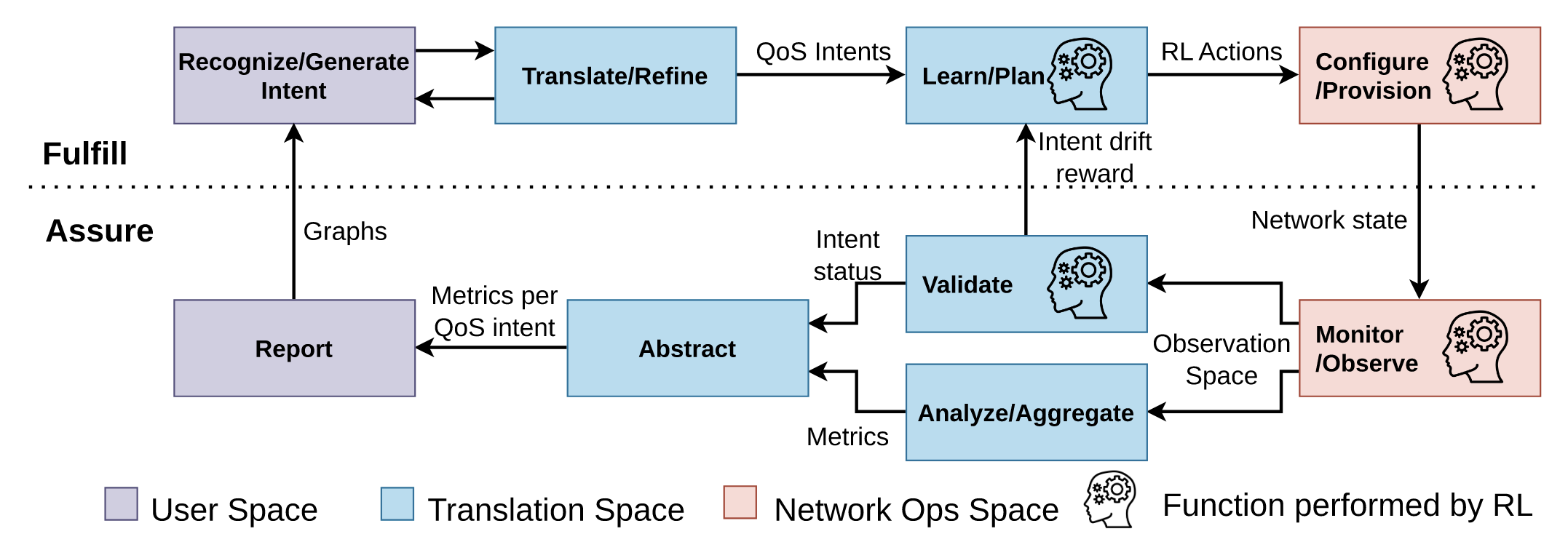
본 그림은 강화학습 기반의 Intent-Aware RRS 동작 단계를 나타내며, 두 개의 closed loops로 구성 됨. 강화 학습 에이전트가 각 루프 내에서 동작함
- Recognize/Generate Intent(의도 인식 및 생성)
- 사용자의 서비스 요청 또는 네트워크 운영자가 설정한 QoS 요구사항(SLA)를 인식하고 이를 Intent로 생성
- 예를 들어, eMBB는 높은 데이터 전송률 요구를, URLLC는 초저지연과 높은 신뢰성을 요구하는 등 각 슬라이스별 의도가 정의됨
- 생성된 의도는 다음 단계에서 네트워크 운영에 적합한 정량적 QoS 목표로 변환됨
- Translate/Refine(의도 변환 및 정제)
- 사용자나 네트워크 운영자가 설정한 Intent를 정량적 QoS로 변환
- 이 단계는 슬라이스별 전송률, 지연 시간, 패킷 손실률 등의 정확한 메트릭으로 의도를 정의하는 과정
- 변환된 QoS 목표는 강화 학습 기반의 Learn/Plan 단계에서 자원 할당 계획 수립에 활용됨
- 이 과정은 자동화되어 있으며, 사람의 개입 없이도 Intent 변화에 따라 자동으로 조정됨
- Learn/Plan(학습 및 계획 수립)
- 강화 학습 에이전트가 현재 네트워크 상태(Observation Space)를 기반으로 자원 할당 정책을 학습
- 에이전트는 Intent Drift를 감지하고 보상 함수를 통해 이를 교정함
- Intent Drift: 실제 네트워크 성능이 의도된 QoS 목표에서 벗어나는 형상
- 학습된 정책은 각 슬라이스에 필요한 자원을 효율적으로 할당하여 QoS 목표를 달성하도록 계획을 수립함
- Configure/Provision(자원 구성 및 할당)
- 학습된 자원 할당 계획에 따라 네트워크 자원을 구성하고 각 슬라이스에 자원을 할당
- 기지국의 RBG와 같은 물리적 자원들이 슬라이스 간에 배분됨
- 네트워크 상태 변화에 실시간으로 적응하여 동적으로 자원 재할당이 이루어짐
- Monitor/Observe(모니터링 및 관찰)
- 네트워크의 실시간 상태 정보를 모니터링하여 현재 성능이 설정된 의도와 일치하는지 확인
- 모니터링하는 메트릭에는 전송률, 지연 시간, 패킷 손실률 등이 포함
- 관찰된 정보는 Observation Space로 전달되어 강화 학습 에이전트가 이후 학습에 사용할 수 있도록 함
- Analyze/Aggregate(분석 및 집계)
- 네트워크에서 수집된 다양한 메트릭 데이터를 분석하고 슬라이스별로 집계하여 QoS 요구가 충족되었는지 평가
- 각 슬라이스의 전송률, 지연 시간, 패킷 손실률 등 핵심 성능 지표를 계산하여 종합적인 네트워크 상태를 파악
- Validate(검증)
- Analyze/Aggregate 단계에서 집계된 성능 메트릭을 바탕으로 현재 네트워크 상태가 의도된 QoS 목표를 충족하는지 검증
- 만약 QoS 목표를 충족하지 못하믄 Intent Drift가 발생했다 간주하고, 이를 보상 함수에 반영하여 학습 과정에서 교정
- Report(보고)
- 최종적으로, 네트워크의 상태와 각 슬라이스의 QoS 성능을 사용자 또는 네트워크 운영자에게 시각적 그래프 및 보고서 형태로 제공
- 보고된 데이터는 의도 변화에 따른 새로운 정책 수립에도 참고
- 두 개의 Closed loop 설명
- Inner Loop
- 강화 학습 에이전트가 주도하는 루프이며, Translate/Refine \(\rightarrow\) Learn/Plan \(\rightarrow\) Configure/Provision 단계를 순환
- 실시간 네트워크 상태 변화에 다라 자원을 동적으로 조정하여 각 슬라이스의 QoS 목표를 충족
- Outer Loop
- 네트워크 운영자 또는 자동화된 시스템이 의도를 생성하고 성능을 보장하는 Recognize/Generate Intent \(\rightarrow\) Report 경로로 이루어짐
- 새로운 Intent가 생성되거나 QoS 목표가 변경될 때 강화학습 에이전트가 학습해야 할 목표르 업데이트
- Inner Loop
2.4.1 Reinforcement Learning Agent
- 강화학습은 최적의 정책 \(\pi\)를 학습하여 누적 보상을 최대화하는 것을 목표로 함. 이 때, 누적 보상은 시간의 따른 보상의 총합으로 정의됨
- SAC 알고리즘은 탐색과 수렴 간의 균형을 유지하여 네트워크 상태 변화에 빠르게 적응하는 강화학습 방식
- Temperature Parameter를 사용해 탐색성과 수렴성을 조정하여 최적의 자원 배분을 보장
2.4.2 Observation Space
- \(\mathbf{O}_n\): step \(n\)에서 상태 \(s_t\)를 나타내는 정보를 포함하는 observation 공간
- \(\mathbf{r}_s\): RAN 슬라이스 intent 벡터들
- eMBB: \(\mathbf{r}_{embb} = [r_{embb}^{req}, l_{embb}^{req}, p_{embb}^{req}]\)
- URLLC: \(\mathbf{r}_{urllc} = [r_{urllc}^{req}, l_{urllc}^{req}, p_{urllc}^{req}]\)
- BE: \(\mathbf{r}_{be} = [g_{be}^{req}, f_{be}^{req}]\)
- \(\mathbf{s}_s\): 슬라이스 메트릭
- \(\mathbf{u}_u\): 사용자 메트릭
Observation 공간에서 슬라이스 메트릭이 결국 사용자 메트릭의 평균으로 계산되기 때문에 이를 반영해 더 적은 차원의 Observation 공간을 재정의할 수 있음 \[\mathbf{O}_{n}^{lim} = [\mathbf{r}_1,..., \mathbf{r}_S, \mathbf{s}_1, ..., \mathbf{s}_{S}]\]
한정된 Observation 공간을 사용함으로써 UE 수가 증가함에 따라 계산의 복잡도가 기하급수적으로 증가하지 않음
또한 Observation 공간과 Reward 함수에서 Batch Normalization을 적용하여
- Gradient 계산 시 parameter 스케일에 대한 의존성을 줄임
- Parameter 초기값에 대한 민감도를 완화하여 학습 초기에 발생할 수 잇는 발산 위험을 방지
- 학습 속도를 향상시키고, Hyperparameter 선택을 쉽게 함
이를 통해,
- Observation 공간 내 다양한 입력(슬라이스별 throughput, latency, packet loss rate 등)의 값 범위가 서로 다르더라도 Batch Normalization을 통해 입력을 정규화하여 효율적 학습이 가능해짐
- 특히, reward 함수에서도 값의 크기를 정규화함으로써 정확한 reward 계산과 정확한 gradient 업데이트가 이루어짐
2.4.3 Action Space
- \(a_s\): 슬라이스 \(s\)에 대한 자원 할당 결정
- \(a_s\)는 [-1, 1] 범위 내에서 결정
- 행동 선택과 자원 할당 맵핑 과정
- 행동 벡터의 샘플링
- 각 시간 스텝 \(n\)에서 강화 학습 에이전트는 가우시안 분포 기반의 Action 벡터 \(\mathbf{A}_n\)을 선택
- \(\mu_s\): 현재 상태 \(s\)에 따라 학습된 평균값
- \(\sigma_s\): 행동의 표준 편차로, 탐색의 정도를 결정
- 이 값은 [-1, 1] 범위로 제한되며, 네트워크 슬라이스별 자원 할당 결정을 나타냄
- 행동 벡터의 샘플링
- 행동을 자원 할당으로 매핑하는 수식
에이전트가 선택한 행동 벡터 \(\mathbf{A}_n\)은 네트워크 시스템의 실제 자원 할당 옵션으로 변환됨. 이는 아래의 수식과 같음 \[index(n) = arg min_{option} d(\mathbf{R}_{comb}, \mathbf{R}_n)\]
- \(\mathbf{R}_{comb}\): 미리 정의된 자원 할당 옵션 집합
- 유클라디안 거리 \(d\): 행동 벡터 \(\mathbf{A}_n\)과 자원 할당 옵션 간의 차이를 측정하는 거리 계산
2.4.4 Intent Drift Reward Calculation and Slice Prioritzation
이 챕터에서는 intent가 설정된 네트워크 슬라이스의 QoS 목표 충족여부에 따라 보상 함수를 정의함. 보상 함수는 네트워크 상태가 intent에서 벗어났을 때(intent drift) 음수의 보상을 부여하여 이를 교정하고, intent를 충족했을 때 보상 값은 0이 됨
- 보상 함수의 전체 구조 보상함수는 슬라이스 유형별로 나뉘어 각 슬라이스의 QoS intent 충족여부에 따라 계산됨
2.4.4.1 eMBB 슬라이스의 보상 구성 요소
\[\text{RW}_{\text{embb}}(n) = -\big( \text{RW}_{\text{embb}}^r(n) + \text{RW}_{\text{embb}}^\ell(n) + \text{RW}_{\text{embb}}^p(n) \big)\]- \(\text{RW}_{\text{embb}}^{r}(n)\): Throughput 보상
- \(\text{RW}_{\text{embb}}^{l}(n)\): 평균 버퍼 지연 시간 보상
\(\text{RW}_{\text{embb}}^{i}(n)\): 패킷 손실률 보상
- Throughput 보상
- \(w_{\text{embb}}^{r}\): Throughput의 intent에 대한 가중치
- \(r_{\text{embb}}^{req}\): eMBB 슬라이스의 요구 throughput
- \(r_{\text{embb}}(n)\): 실제 throughput
- 평균 버퍼 지연 시간 보상
- \(w_{\text{embb}}^{l}\): 평균 버퍼 지연 시간에 대한 가중치
- \(l_{\text{embb}}^{req}\): 요구 버퍼 지연 시간
- \(l_{max}\): 허용 가능한 최대 지연 시간
- 패킷 손실률 보상
- \(w_{\text{embb}}^{p}\): 평균 버퍼 지연 시간에 대한 가중치
- \(p_{\text{embb}}^{req}\): 요구 버퍼 지연 시간
- $$p_{\text{embb}}(n): 실제 패킷 손실률
2.4.4.2 URLLC 슬라이스의 보상 구성 요소
\[\text{RW}_{\text{urllc}}(n) = -(\text{RW}_{\text{urllc}}^{r}(n) + \text{RW}_{\text{urllc}}^{l}(n) + \text{RW}_{\text{urllc}}^{p}(n))\]- 각 메트릭은 eMBB 슬라이스와 동일한 방식으로 계산되며, 각 메트릭에 대한 가중치가 설정됨
2.4.4.3 BE 슬라이스의 보상 구성 요소
Long-term throughput과 5-percentile throughput을 기준으로 정의됨
$$ \text{RW}{\text{be}}(n) = -(\text{RW}{\text{be}}^{g}(n) + \text{RW}_{\text{be}}^{f}(n))
- Long-term throughput 보상
- 5-percentile throughput 보상
- 네트워크가 모든 슬라이스의 QoS 요구를 동시에 충족하지 못하는 경우, eMBB와 URLLC 슬라이스에 높은 우선순위를 부여
- 각 메트릭의 가중치는 슬라이스 간 우선순위를 반영하며, 가중치의 합이 1이 되도록 설정하여 보상을 정규화
2.4.5 Baselines
- PF(Proportioanl Fairness) 스케쥴링
3. Take Away
- 시뮬레이션 파라미터들을 참고하여 NS-3에서 사용
- 10 p.m. - 6 a.m. 까지 사용자를 고정시킨 후 cell on/off를 실행
- 예측 알고리즘과 on/off 알고리즘의 결합